Evaluating an AI agent before it takes action is different from reviewing a chatbot response. A chatbot may only answer, summarize, or suggest. An AI agent may call tools, update records, trigger workflows, send messages, retrieve sensitive information, or change the state of a business process. That shift makes evaluation one of the most important parts of careful adoption of agentic AI services.
Many teams still evaluate agents by checking whether the response sounds useful. That is not enough. An agent can sound confident and still choose the wrong tool, use incomplete context, bypass a permission boundary, or continue when it should escalate. For production use, the real question is not only whether the agent gave a good answer. The real question is whether the agent behaved correctly before, during, and after action.
Recent research shows why this matters. A survey on LLM-based agent evaluation describes agents as systems that can plan, reason, and use tools in dynamic environments, while also identifying gaps in safety, robustness, cost-efficiency, and scalable fine-grained evaluation methods. The 2025 AI Agent Index reviewed 30 deployed agentic AI systems and found that most developers still share limited information about safety, evaluations, and societal impact. These signals show that evaluation is becoming central to agent adoption, but the industry is still building the discipline around it.
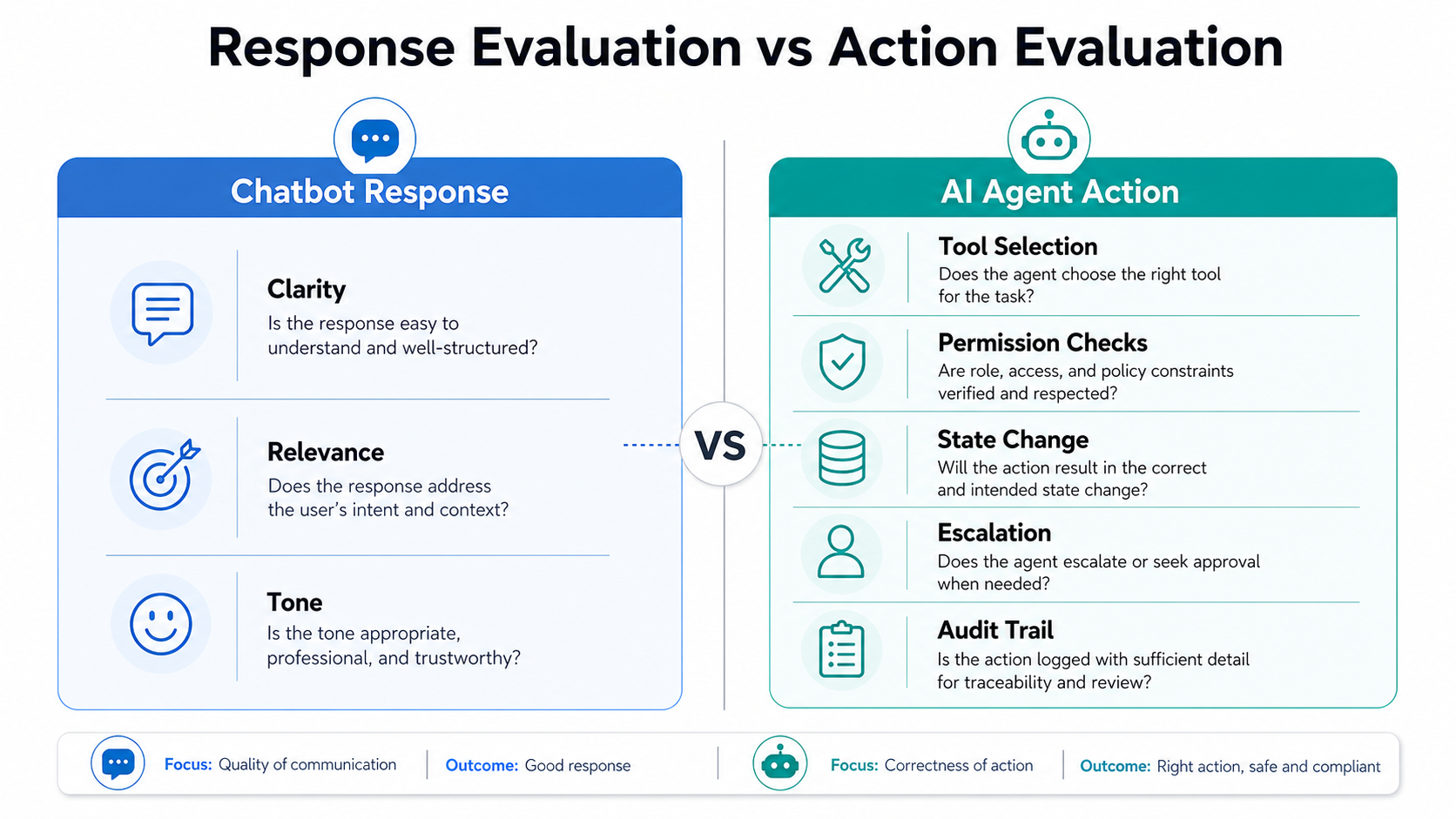
Why Response Quality Is Not Enough
Response quality checks whether the agent communicates well. Action quality checks whether the agent operates correctly. That distinction is important because production failures often happen outside the text response.
An agent may generate a clear explanation but call the wrong API. It may summarize a case well but use outdated context. It may recommend the right next step but execute it without approval. It may complete a workflow but leave the system in an inconsistent state.
This is why evaluation must move beyond answer review. Teams need to inspect the full path from user intent to final system outcome. That path includes the input, available context, retrieved data, reasoning trace, selected tool, executed action, permission boundary, approval status, resulting state, and escalation decision.
The evaluation standard should match the risk of the action. A low-risk information retrieval agent may need lighter evaluation. An agent that updates records, triggers communications, handles regulated data, or affects customer outcomes needs a stronger evaluation framework before it is allowed to act.
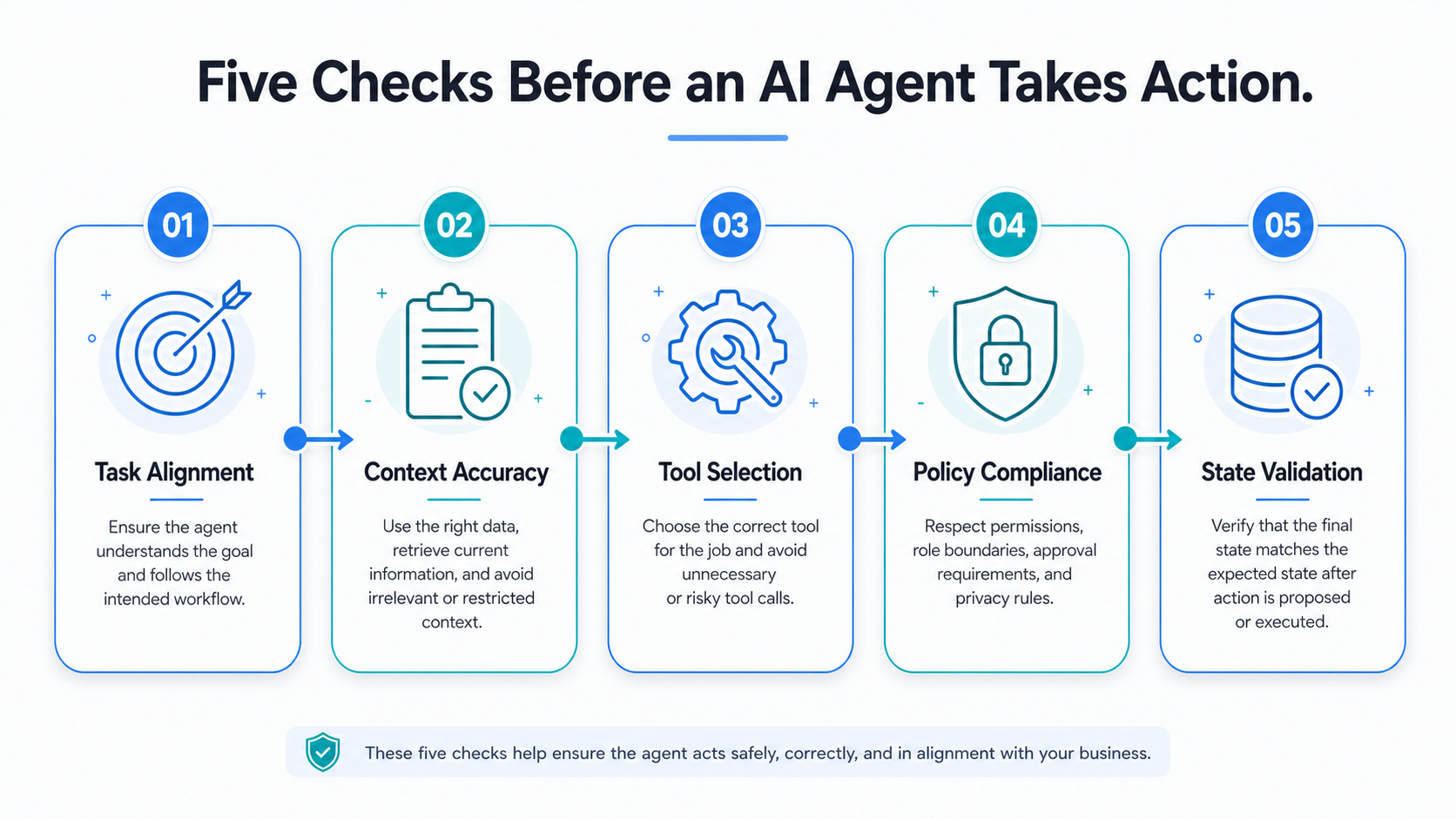
The Five Checks Before an AI Agent Takes Action
A practical evaluation framework should begin with five checks. These checks help the team decide whether the agent is ready to move from recommendation to controlled execution.
The first check is task alignment. The team should verify that the agent understood the user's goal and followed the intended workflow. The agent should not solve a nearby problem when the requested task requires a different process.
The second check is context accuracy. The agent should use the right data, retrieve current information, and avoid irrelevant or restricted context. A good response based on the wrong context is still a failed action.
The third check is tool selection. The agent should choose the correct tool for the job and avoid unnecessary tool calls. This matters because tool access is where an agent becomes operational rather than conversational.
The fourth check is policy compliance. The agent should respect permissions, role boundaries, approval requirements, privacy rules, and escalation policies. Safety should not depend only on the wording of a prompt.
The fifth check is state validation. After an action is proposed or executed, the system should verify that the final state matches the expected state. This is especially important when the agent updates records, changes workflow status, or triggers downstream processes.
Test the Agent Through Realistic Scenarios
A strong evaluation process should test the agent against realistic scenarios, not only ideal examples. Real users provide incomplete instructions, ambiguous requests, conflicting information, and edge cases. Business systems also contain changing records, failed API calls, permission mismatches, and workflow exceptions.
Scenario testing should include normal cases, edge cases, risky cases, and refusal cases. The goal is to understand how the agent behaves when the path is not clean. A production agent should not only succeed when everything is clear. It should also know when to ask for clarification, when to stop, and when to escalate.
IBM's research on deploying a generalist agent in enterprise production shows how complex real evaluation can become. Their enterprise pilot introduced a benchmark with 26 tasks across 13 analytics endpoints, and the paper highlights scalability, auditability, safety, and governance as production requirements. That example shows why agent evaluation must reflect real workflow complexity rather than isolated demo performance.
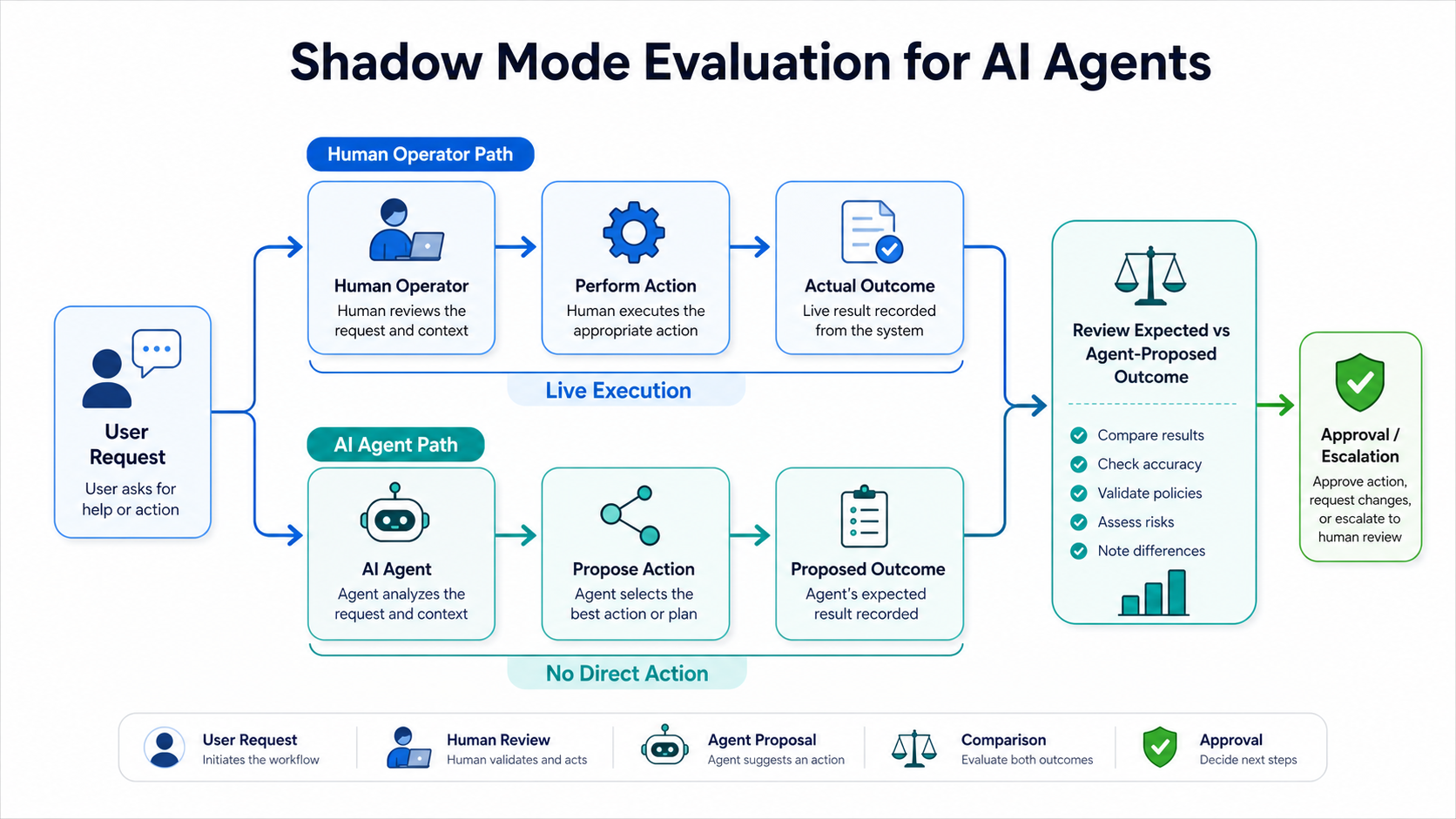
Use Shadow Mode Before Live Execution
Shadow mode is a useful bridge between offline testing and live action. In shadow mode, the agent observes the workflow or proposes actions without executing them directly. Human operators or existing systems continue to perform the actual work.
This stage helps the team compare agent decisions against real outcomes. The team can inspect whether the agent selected the right action, used the right context, respected policy, and produced a recommendation that matched the expected workflow. Because the agent is not yet executing actions, shadow mode reduces risk while still producing practical evaluation data.
Shadow mode also exposes hidden workflow rules. Many organizations discover that their processes depend on informal judgment, undocumented exceptions, or human workarounds. These discoveries are valuable because they show what must be formalized before the agent receives more autonomy.
Validate Tool Calls Before Expanding Autonomy
Tool-call validation is one of the most important parts of evaluating an AI agent. Before an agent can act, the team should know whether each tool call was necessary, allowed, correctly parameterized, and safe for the current workflow state.
For example, a tool call that retrieves a record may be acceptable in many cases. A tool call that updates a customer profile, changes an appointment, sends a message, or triggers a financial process requires stricter review. The evaluation layer should classify tool calls by risk and apply different controls based on the action.
This is where careful adoption becomes practical. Low-risk actions may be allowed after testing. Medium-risk actions may require approval. High-risk or irreversible actions may remain human-only until the system has stronger controls, better monitoring, and enough evidence of stable performance.
A survey of 45 data science agents found that more than 90 percent lacked explicit trust and safety mechanisms. That finding is a warning for teams adopting agentic systems. Tool access should not be expanded simply because an agent is capable. It should be expanded only when governance, testing, and state validation are ready.
Evaluate Escalation Behavior
A safe AI agent should not always try to complete the task. Sometimes the right behavior is to pause, ask a question, request approval, or hand the task to a human. This is why escalation behavior must be tested before the agent takes action.
Escalation should happen when the request is ambiguous, the context is incomplete, the action is outside the agent's allowed scope, the user lacks permission, the outcome could be high-risk, or the agent cannot verify the final state. These conditions should be designed into the system, not left to the agent's judgment alone.
The team should test whether the agent escalates at the right time. Over-escalation makes the agent less useful. Under-escalation creates operational risk. The goal is to tune the system so the agent can act confidently in safe conditions and defer reliably when uncertainty or risk increases.

Monitor Behavior After Release
Pre-action evaluation reduces risk, but it does not remove the need for post-release monitoring. Agent behavior can change when prompts are updated, tools are modified, context pipelines change, business rules evolve, or users discover new ways to interact with the system.
A production agent should be monitored through logs, replay, audit trails, and behavior reviews. The team should be able to see what the agent saw, what it selected, what it did, what changed, and why the outcome was accepted or escalated.
The most useful monitoring signals include tool-call accuracy, approval rate, escalation rate, user correction rate, policy violations, failed actions, repeated edge cases, latency, cost per workflow, and incident frequency. These signals help the team decide whether to expand autonomy, tighten controls, or redesign part of the workflow.
Build Evaluation Into the Adoption Roadmap
Evaluation should not be added at the end of an agentic AI project. It should be part of the adoption roadmap from the beginning. The team should define expected behavior before implementation, test realistic scenarios before release, use shadow mode before live execution, and monitor behavior after launch.
This approach changes the adoption conversation. Instead of asking whether the agent is impressive, the team asks whether it is ready for a specific level of responsibility. That is the right question for production systems.
Careful adoption of agentic AI services means the agent earns autonomy through evidence. It should first prove that it can recommend correctly. Then it can propose actions. Then it can execute low-risk actions. Then it can operate within wider workflows under monitoring and governance. Each stage should be based on observed behavior, not assumption.
Conclusion
AI agents should not take action in production just because they can complete a demo. They should take action only when the organization can evaluate their behavior, inspect their tool use, verify their state changes, monitor their outcomes, and stop or escalate them when needed.
The safest evaluation question is simple. Before the agent acts, can the team prove that the action is allowed, correct, observable, and reversible where possible?
That question turns agentic AI from an experiment into an operational system. It also creates the foundation for adoption that is not only fast, but controlled, measurable, and ready for real business workflows.