AI pilots are easy to start and difficult to operationalize. A pilot can show that an AI agent is capable of answering questions, summarizing records, suggesting next steps, or calling a tool in a controlled demo. Production is different because the agent begins interacting with live workflows, real data, permission boundaries, business rules, and operational consequences.
That is where careful adoption of agentic AI services becomes important. The goal is not to slow down adoption. The goal is to prevent teams from confusing a promising experiment with a production-ready system.
Recent market signals show why this matters. Agentic AI is expected to create hundreds of billions of dollars in business value over the next few years, but fully scaled deployment remains rare. Reported industry data suggests that only a small percentage of organizations have fully scaled AI agent deployments, while trust in autonomous agents has declined. This gap shows the real adoption problem. Organizations are interested in agents, but they are not yet confident that agents can operate safely and reliably inside business systems.
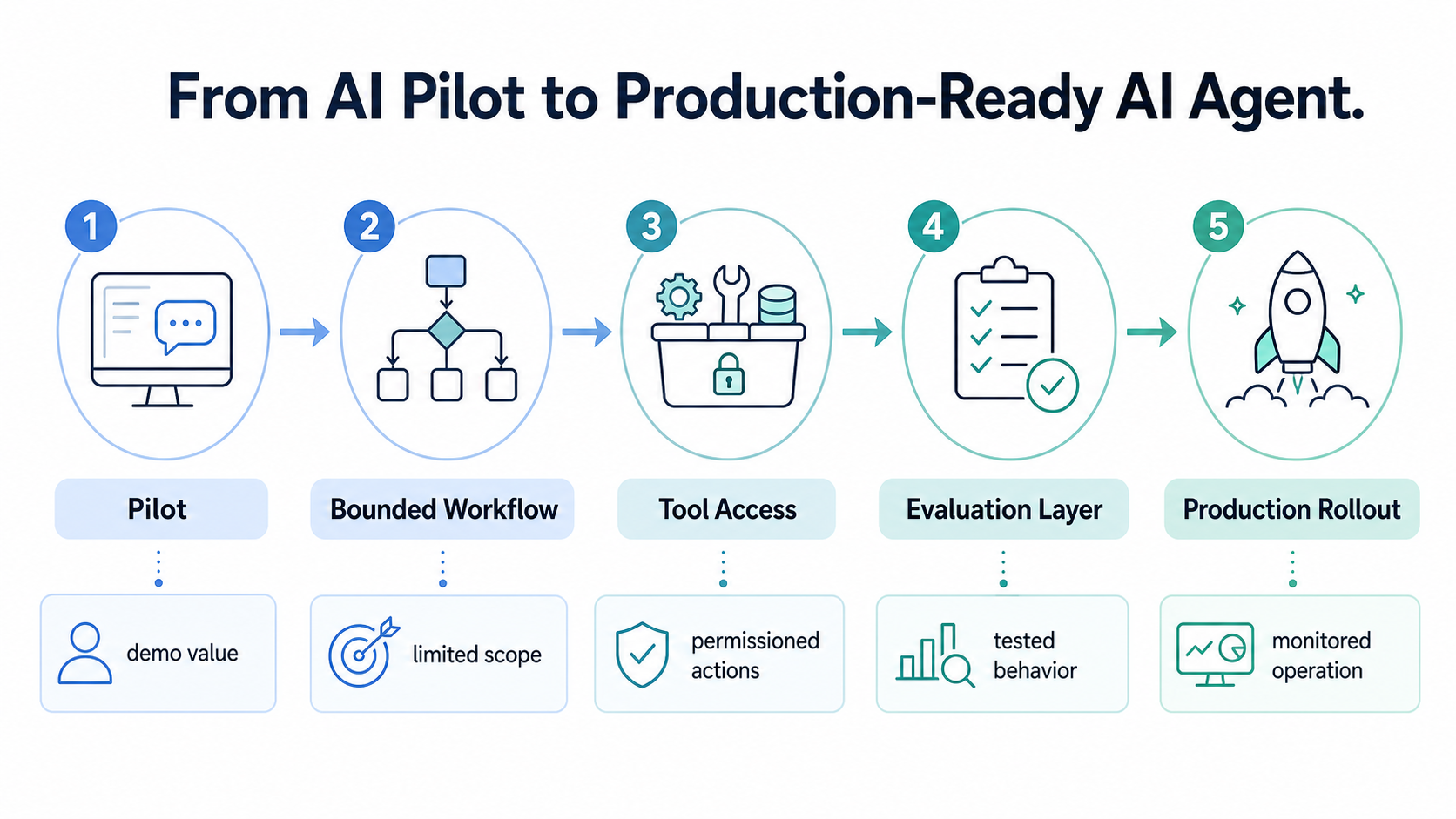
Why AI Pilots Fail Before Production
Most AI pilots fail because they are designed to prove capability, not operational readiness. A pilot usually happens in a narrow environment where the inputs are known, the workflow is supervised, and the cost of failure is low. Production requires a different standard.
A production-ready AI agent must handle incomplete information, changing context, user ambiguity, permission limits, tool errors, and unexpected workflow states. It must also know when not to act. This is the main difference between a helpful AI feature and an agentic service that can operate inside a business process.
The problem is not that agents cannot perform useful work. The problem is that many systems are not ready for agents to perform that work safely. Existing business systems often contain hidden rules, fragmented data, inconsistent permissions, and workflows that depend on human judgment. When an agent is added without mapping these constraints, the organization creates risk instead of leverage.
Start With One Bounded Workflow
The first production use case should not be broad. It should be narrow, measurable, and easy to observe. A good starting workflow has clear inputs, clear outputs, known decision points, and limited operational risk.
For example, an agent can begin by triaging incoming requests, preparing summaries, recommending actions, routing cases, or drafting responses for review. These workflows create value without immediately giving the agent full autonomy over sensitive actions.
Bounded autonomy is the key principle. The team should define what the agent can read, what it can recommend, what it can execute, what requires approval, and what must always be escalated to a human. This creates a controlled operating area where the agent can be useful without becoming unpredictable.
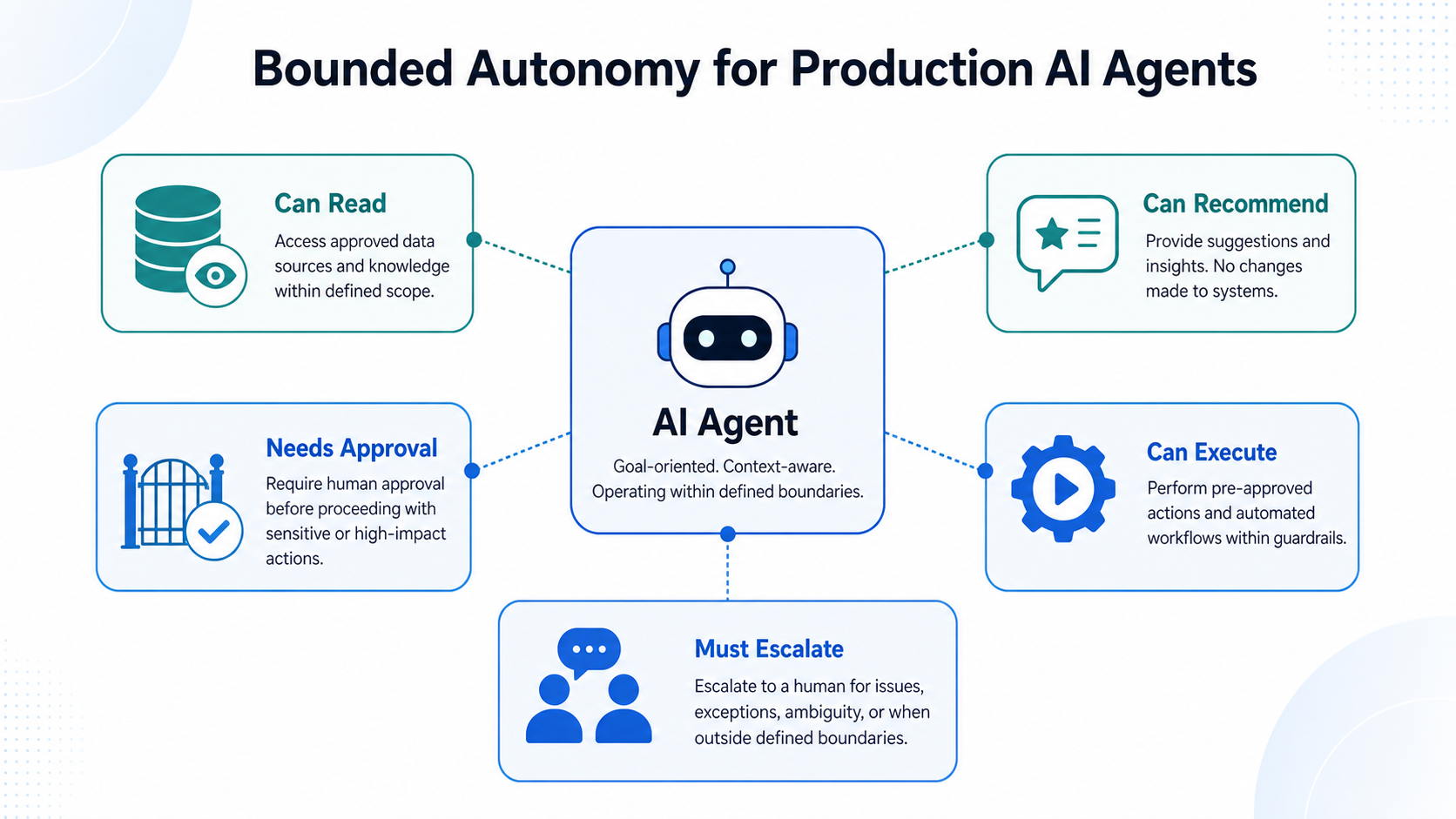
Separate AI Assistance From Agentic Action
A common mistake is treating every AI capability as agentic. Not every workflow needs an autonomous agent. Some steps should remain deterministic because they follow fixed business logic. Some steps should use AI assistance because they require summarization or recommendation. Some steps may justify agentic action because they require context interpretation, tool selection, or multi-step execution.
This separation makes adoption safer. Known business rules should remain in controlled software logic. High-risk actions should remain behind approval gates. Agentic reasoning should be used where flexibility is valuable, not where predictability is already available.
A production-ready agentic service is therefore not just a model connected to tools. It is a workflow design where deterministic logic, AI assistance, human review, and agentic action are deliberately placed in the right parts of the process.
Govern Tool Access Before Expanding Autonomy
Tool access is the moment where an AI agent moves from conversation into operation. Once an agent can call APIs, update records, send messages, trigger workflows, or change business state, governance becomes essential.
Every tool should be classified by risk. Read-only tools are usually lower risk because they retrieve information without changing the system. Write tools need stronger controls because they modify records. External action tools need even more care because they may send communications, trigger payments, create tickets, notify users, or activate downstream processes.
Before production rollout, the team should define permission inheritance, approval rules, escalation paths, audit logs, and rollback options. The agent should not receive broad tool access simply because it performed well in a pilot.

Build Evaluation Before Production Rollout
Evaluation is one of the biggest gaps between AI pilots and production AI agents. A pilot often checks whether the answer looks useful. Production evaluation must check whether the behavior is correct.
The evaluation layer should answer practical questions. Did the agent use the right context? Did it select the correct tool? Did it follow the right permission boundary? Did it change the correct state? Did it escalate when uncertainty increased? Did it avoid actions that were outside its allowed scope?
This is why output testing alone is not enough. Agentic systems need full-flow testing. They should be tested across realistic scenarios, edge cases, ambiguous requests, failed tool calls, permission conflicts, and risky action paths.
A strong evaluation process should begin before launch and continue after launch. Pre-production testing helps identify unsafe behavior before users are affected. Post-production monitoring helps detect drift, repeated failure patterns, and workflow conditions that were not visible during the pilot.
Move Through Shadow Mode Before Controlled Execution
Shadow mode is one of the safest bridges between pilot and production. In shadow mode, the agent observes the workflow or proposes actions without executing them directly. This allows the team to compare agent decisions against human decisions, existing rules, or expected outcomes.
After shadow mode, the agent can move into controlled execution. In this stage, low-risk actions may be executed directly, while medium-risk actions require approval and high-risk actions remain human-owned. This staged rollout helps the organization build confidence through evidence rather than assumption.
The rollout should also include monitoring from the beginning. Logs should capture the user request, context used, tool selected, action taken, approval status, final outcome, and any escalation. Without this visibility, teams cannot understand why the agent behaved in a certain way.
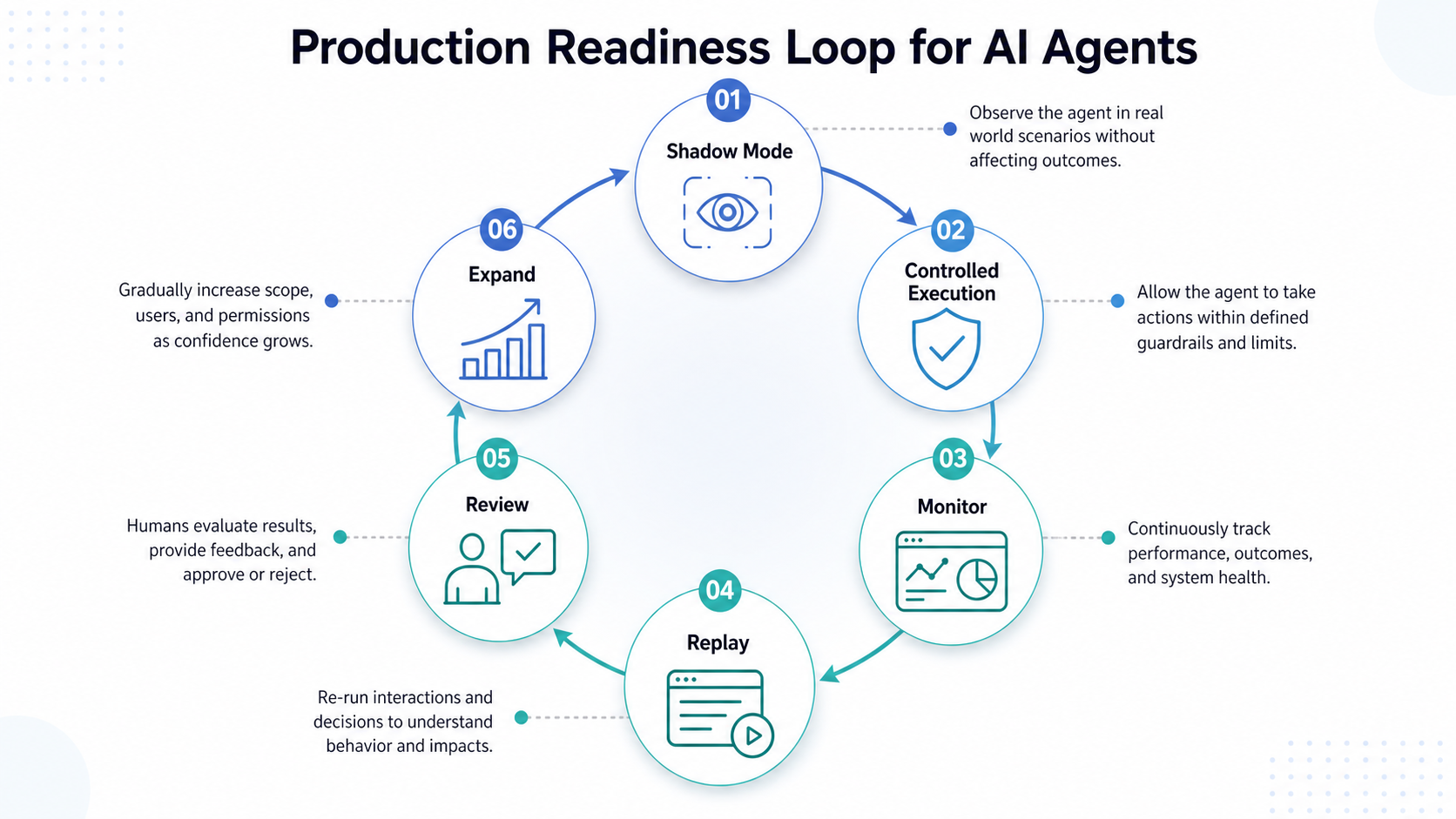
Define Production Success Metrics
Production readiness should be measured with more than user satisfaction. A useful agent can still be unsafe, expensive, inconsistent, or difficult to audit. Teams should measure task completion rate, escalation rate, approval rate, tool-call accuracy, policy violations, user correction rate, latency, cost per completed workflow, and incident frequency.
These metrics help the team decide whether the agent is ready for broader autonomy. They also prevent a common adoption mistake where teams scale because the demo looked good, not because the system performed reliably.
The best production metrics connect agent behavior to business outcomes. The organization should know whether the agent reduced manual effort, improved response time, increased process consistency, lowered support load, or helped teams handle more work without losing control.
Expand Only After Evidence
Careful adoption does not mean staying in pilot mode forever. It means expanding after the first workflow proves that the agent can operate safely, measurably, and repeatably.
The first production workflow creates the foundation. It reveals which data sources are reliable, which tools need stricter permissions, which edge cases create risk, which evaluation tests matter, and which human review points are necessary. Once that foundation is stable, the organization can expand to adjacent workflows with more confidence.
This is the practical path from AI pilot to production-ready AI agent. Start small, define boundaries, govern tool access, test behavior, observe outcomes, and expand through evidence.
Conclusion
Careful adoption of agentic AI services is not about delaying innovation. It is about making agentic AI usable in real operations. AI pilots prove possibility. Production-ready AI agents require boundaries, governance, evaluation, monitoring, and accountability.
The safest question is not, "What can the agent do?" The better question is, "What can this system safely allow the agent to do, and how will we verify it before and after action?"
Organizations that answer that question well will move faster than teams that rush from demo to deployment. They will not only build agents. They will build agentic services that are ready for real work.